Your Business Is Losing Money On Wasted AWS Costs
Go beyond basic cost tracking with real, actionable strategies to reduce wasted AWS spend and boost efficiency. Setup takes minutes and we instantly begin searching for the highest ROI opportunities.
Is your successful venture leaking profits without you even realizing? It’s a common blind spot for thriving businesses. As the revenue rolls in, unseen wasted cloud costs can silently drain your hard-earned gains.
Most growing businesses waste 25-35% of their AWS spend
It starts small with an MVP running on just a few resources. But as your app grows, so do the bills, often snowballing out of control until they reach amounts you never thought possible. We’ve been there and we can help!
Wasted Resources Burn Budgets
From idle instances to underutilized storage, countless resources sit unused while continuing to rack up charges. These inefficiencies often go unnoticed, eating into your bottom line and reducing your return on investment.
AWS Cost Creep Is Real
AWS costs tend to rise between 3-7% monthly on a compounding basis for the average growing business, driven by hidden inefficiencies, scaling applications, and under-optimized resources. Without intervention, these increases can significantly impact your bottom line.
Native Tools Aren't Good Enough
AWS’s native cost tools scatter your data, making actionable insights nearly impossible to find. Spend Shrink unifies your billing into one clear dashboard, exposing savings opportunities hidden in the chaos.
What Makes Us Special
The #1 ROI Focused AWS Cost Optimization Tool
Our solution was built from the start to ensure it brings high value and saves time for both engineering teams and business stakeholders.
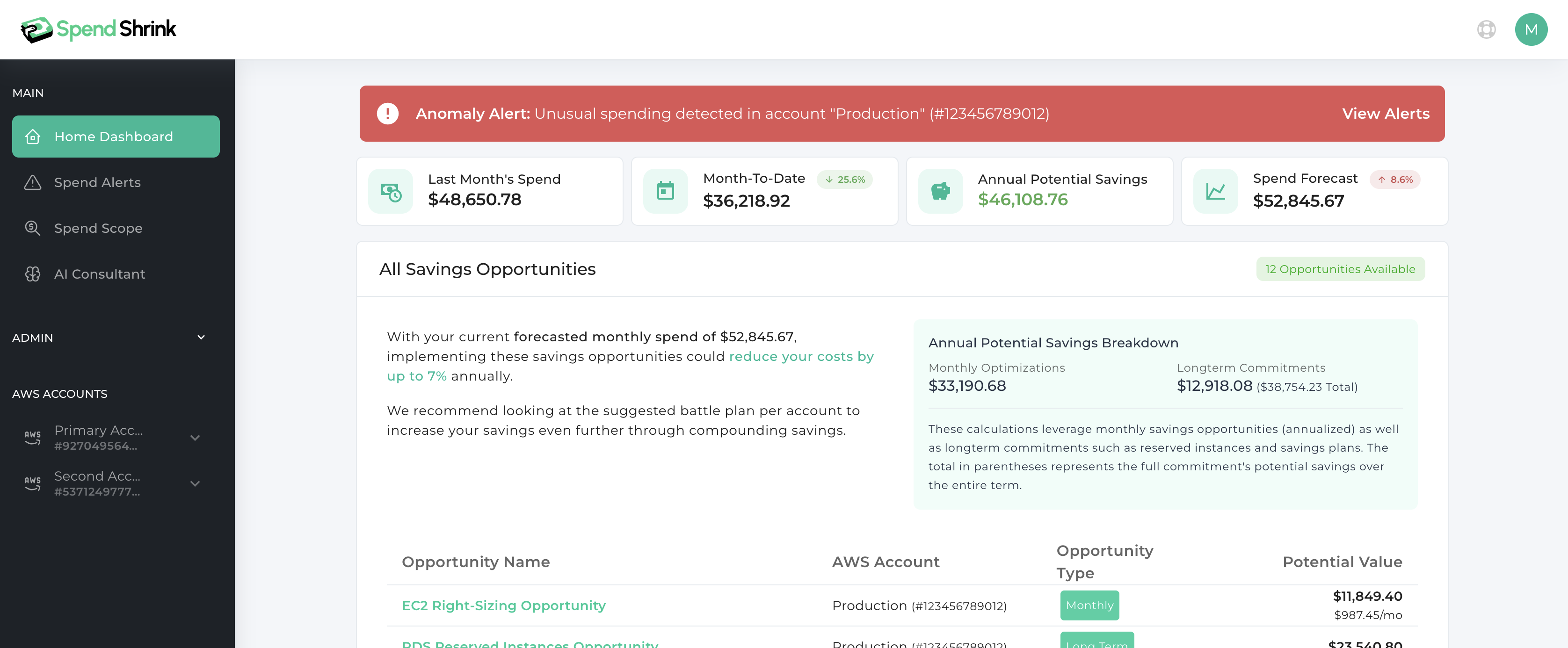
Premium Savings Opportunities
Unlock hidden savings with targeted recommendations for each AWS account. Our platform analyzes your spend to identify cost-cutting measures and provides a clear, actionable battle plan. With strategic guidance on optimizing resources, you can reduce waste and boost your returns.
- Tailored Results Per AWS Account
- Strategic Battle Plans
- Prioritized Steps For Maximum ROI
- Opportunity Specific Helpful Info
Uncover Costs With Spend Scope
Spend Scope is our one-of-a-kind search tool that lets you explore your AWS spend in seconds. Whether you need a high-level overview or a deep dive into detailed cost data, its intuitive queries and dynamic visualizations empower you to uncover savings instantly.
- No Difficult Query Languages
- High Level Cost Breakdowns
- Granular Spend Data (Deep Dive)
- Relevant Monthly & Daily Data
- Dynamic Charts & Breakdowns
Expert Help From AI Consultant
Leverage our AI Consultant for context-aware recommendations and strategic advice. It analyzes your conversation relevant spending patterns and data automatically and suggests the best cost-saving measures to optimize your AWS investments.
- No Training On Your Data
- Leverages Secure OpenAI API
- Optional Custom Business Context
- Built In Opportunity Widgets
- Limited Free Tier Access
Our Pricing
Discover Unmatched AWS Savings for Any Business, Big or Small 🚀
Whether you’re a lean startup or a growing enterprise, Spend Shrink gives you the tools to cut waste and optimize your AWS spend. Start today and see how much you can save!
Free Tier
-
Up To 3 AWS Accounts
-
Up To 5 Additional Users
-
Limited AI Consultant
-
Limited Spend Scope
-
Limited Spend Insights
-
Full Spend Overviews
-
Spend Alerts
-
Savings Opportunity Details
Premium Tier
Our powerful premium tier grants full access to our entire platform with unlimited additional users and AWS accounts. Payment is required to unlock savings opportunities.
-
Everything Included In Free Tier
-
Unlimited AI Consultant
-
Access All Savings Opportunities
-
Savings Opportunity Battle Plans
-
Full Access To Spend Scope
-
Full Access To Spend Insights
-
Export Opportunity CSVs For Scripting
-
Unlimited Users At No Cost
-
Unlimited AWS Accounts
-
More Powerful AI Consultant Model
-
Premium Customer Support
-
Cancel Anytime (Hassle Free!)
3% Of Total Monthly AWS Spend Per Month ($300/mo minimum) *Discounted rate available for 1-3 year term enterprise contracts.
Designed To Save Your Time And Money
SpendShrink goes beyond tracking your cloud spend by consolidating scattered data into a unified, intuitive dashboard. Our proven strategies deliver real, measurable savings with powerful analytics and proactive alerts, optimizing your AWS investments without the hassle of traditional tools.
Spend Scope
Spend Scope is our natural language search tool that lets you explore your cloud spend in seconds. Whether you need a high-level summary of resources like EKS clusters and load balancers or a deep dive into daily cost report details with dynamic charts, Spend Scope makes the discovery process fast and intuitive.
Detailed Insights
The Detailed Insights page offers an in-depth look at your cloud costs with intuitive tabs for services such as EKS clusters and S3 storage. You get a granular breakdown of each cost driver, making it easier to pinpoint inefficiencies and understand the nuances behind your spending.
Account Cost Overview
Our Account Cost Overview page provides a clear snapshot of your AWS spending for each individual account based on the services actually running. Quickly identify resource-intensive services and make informed decisions without the noise of aggregated data.
AI Consultant
The AI Consultant is designed to help support your decision-making by automatically accessing relevant processed data and offering expert recommendations. It answers questions about your specific accounts with context-aware insights, helping you optimize your cloud spend and manage complex cost scenarios with ease.
Actionable Opportunities
The Opportunities page compiles tailored recommendations and a strategic battle plan for each AWS account. It guides you through the best order of operations, such as prioritizing spot instances before compute savings plans, so you can maximize your returns and reduce waste with confidence.
Spend Alerts
Our Optional Spend Alerts let you monitor AWS spending with customizable Slack or email notifications. They support both individual and organizational views and deliver insights into forecasted, total, and service-specific costs. Built-in anomaly detection requires only threshold settings, providing flexible oversight across any accounts.
The Spend Shrink Difference
Achieve significant AWS cost savings with our no-risk guarantee, quick deployment, and tailored strategies designed for maximum ROI.
Risk-Free 7-Day Money-Back Guarantee
We believe in transparency and results. If Spend Shrink doesn’t deliver tangible AWS cost reduction opportunities in your first 7 days, you can cancel and get every penny back. No hoops, no hassles, just real savings or a full refund.
Rapid Setup & Immediate Insights
Don’t waste weeks navigating complex cloud tools. With Spend Shrink, you can connect your AWS account in minutes and start identifying hidden cost-saving opportunities almost instantly.
Tailored Strategies for Maximum ROI
Every business is unique, and so is your AWS spend. We dive deep into your usage patterns to deliver customized recommendations that deliver up to 30% savings, without sacrificing performance or reliability.
Sneak Peek Your Savings Potential Today!
Connect your AWS account and see exactly how much you could save, all without a credit card. Get a preview of real cost-cutting opportunities and start planning your savings journey.